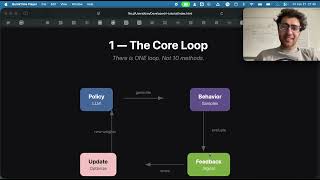
Media Summary: In this AI Research Roundup episode, Alex discusses the paper: 'Sharing is Caring: Efficient LM Are you ready for a paradigm shift in how we train AI, especially Large Language Models (LLMs)? Discover Swarm Sampling ... This paper addresses rollout generation as a major bottleneck in
Sapo Decentralized Rl Post Training - Detailed Analysis & Overview
In this AI Research Roundup episode, Alex discusses the paper: 'Sharing is Caring: Efficient LM Are you ready for a paradigm shift in how we train AI, especially Large Language Models (LLMs)? Discover Swarm Sampling ... This paper addresses rollout generation as a major bottleneck in In this AI Research Roundup episode, Alex discusses the paper: 'Soft Adaptive Policy Optimization(2511.20347v1)' This work ... Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... RollPacker: Taming Long-Tail Rollouts for
In this exclusive guest lecture for the Youth AI Initiative, we hosted Maxime Labonne (Head of Weintroduce INTELLECT-2, the first globally distributed reinforcement learning ( At Ray Summit 2025, Haoran Li from Character AI shares how the company powers its massive AI entertainment ... Instead of jumping between two repositories, developers can stay inside Dexbotic and start the complete Curated AI research intelligence covering May 2025 to May 2026. This video examines the most impactful research on ... We introduce OpenDiLoCo, an open-source implementation and replication of DeepMind's Distributed Low-Communication ...

![[Daily Podcast] SAPO: Decentralized RL Boosts LM Post-Training Efficiency](https://i.ytimg.com/vi/MvSFHgrakuA/mqdefault.jpg)