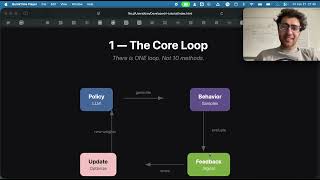
Media Summary: Introducing system integrated guess decoding, an 🔹 Addresses the cost of rollout generation, one of the biggest bottlenecks in RL post-training on Frontier LLM. 🔹 Proposes a ... Alexandre Piché and Dzmitry Bahdanau present PipelineRL, a high-performance reinforcement learning (
Accelerating Rl Post Training Rollouts - Detailed Analysis & Overview
Introducing system integrated guess decoding, an 🔹 Addresses the cost of rollout generation, one of the biggest bottlenecks in RL post-training on Frontier LLM. 🔹 Proposes a ... Alexandre Piché and Dzmitry Bahdanau present PipelineRL, a high-performance reinforcement learning ( At Ray Summit 2025, Haoran Li from Character AI shares how the company powers its massive AI entertainment ... Learn more: Learn to align and optimize LLMs for real-world applications through At Ray Summit 2025, Tyler Griggs from UC Berkeley and Sumanth Hegde from Anyscale share how SkyRL—a modular, ...
check out prime intellect's envrionment hub to publish, explore and use I'm far more optimistic about the state of open recipes for and knowledge of In this AI Research Roundup episode, Alex discusses the paper: 'RubricEM: Meta- The frontier of LLM research has shifted decisively toward Curated AI research intelligence covering May 2025 to May 2026. This video examines the most impactful research on ... In this video, I will give you the "big picture" that makes everything click when it comes to learning Reinforcement Learning.
Model internals encode rich information about how a large language model (LLM) processes its This paper studies how Experience Replay can make