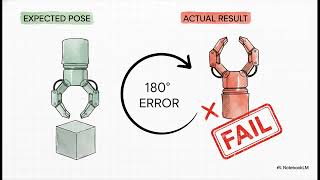
Media Summary: From 35 raw RRT* waypoints down to 3 after shortcutting, then a time-optimal 2.659-second trajectory executed with 0.0037 rad ... 5500+ average reward TD3 policy trained for 7M+ timesteps. Check here for github repo: ... This video presents a comprehensive benchmark comparison of multiple Deep Reinforcement Learning algorithms on the ...
Mujoco Robotics Lab 4 Motion - Detailed Analysis & Overview
From 35 raw RRT* waypoints down to 3 after shortcutting, then a time-optimal 2.659-second trajectory executed with 0.0037 rad ... 5500+ average reward TD3 policy trained for 7M+ timesteps. Check here for github repo: ... This video presents a comprehensive benchmark comparison of multiple Deep Reinforcement Learning algorithms on the ... Lightwheel AI offers physically realistic and interactive assets designed to accelerate Embodied AI simulation in IsaacSim and ... Shantanu covers the first of many simulation environments we'll be rolling out this summer. First up is MIT - December 2, 2022 Yuval Tassa "Predictive Sampling: Real-time behavior synthesis with