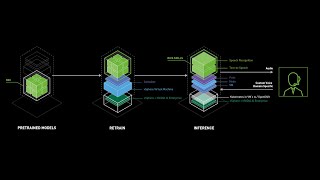
Media Summary: In this episode, we sit down with Solution Architect Robert Alvarez to discuss the technology behind Pure Key-Value Accelerator ... Don't miss out! Join us at our next Flagship Conference: KubeCon + CloudNativeCon Europe in London from April 1 - 4, 2025. This YouTube video delves into the growing popularity of generative
Accelerating Ai Inference Workloads - Detailed Analysis & Overview
In this episode, we sit down with Solution Architect Robert Alvarez to discuss the technology behind Pure Key-Value Accelerator ... Don't miss out! Join us at our next Flagship Conference: KubeCon + CloudNativeCon Europe in London from April 1 - 4, 2025. This YouTube video delves into the growing popularity of generative Watch this webinar for an overview of key Memory, not compute, is rapidly becoming the limiting factor for scaling modern Explore how CoreWeave, a specialized cloud provider, delivers a massive scale of NVIDIA GPUs, including NVIDIA L40S GPUs ...